Tips.6 本当にCOUNT(*)は遅いのか?COUNT(列名)は速いのか?~処理時間を計測~
SELECT文であるテーブルの件数そのものを取得したい場合に、どのようなSQLを書くでしょうか?
通常は「SELECT COUNT(*) FROM [テーブル名];」だと思うのですが。。。
しかし、いろいろ調べてみると、COUNT(*)は遅いので、使用すべきではないという記述をしているサイトが多数あります。
「SQLを速くするぞ」
http://www.geocities.jp/mickindex/database/db_optimize.html#LocalLink-count「SQLを少しでも高速化するためのチューニング」
「速いSQLを書くコツ!!」
http://pg123-undo.blogspot.com/2011/11/sql.html「Oracle SQL パフォーマンス」
https://sites.google.com/site/orapeform/sql_minaoshi
そんなにCOUNT(*)は遅いのでしょうか?
私の経験でも、いくつかの大手ベンダーでSQL記述時の規約としてCOUNT(*)の使用を禁止している企業もありました。
しかも、ご丁寧に「COUNT(*)は遅いので、代わりに COUNT([プライマリキー列名])を使用するように」「COUNT(*)は、全ての列を参照するので、無駄なデータアクセスが発生し、、、」
などと書かれていたりします。
COUNT(*)で無駄なデータアクセスが発生?!
そうでしたでしょうか。
マニュアルを見てみましょう。
Oracle® Database SQL言語リファレンス 12cリリース1 (12.1)
https://docs.oracle.com/cd/E96517_01/sqlrf/COUNT.html#GUID-AEF08B79-024D-4E3A-B362-9715FB011776
アスタリスク(*)を指定すると、このファンクションは重複値およびNULL値を含むすべての行を戻します。
COUNTは、問合せによって戻された行の数を戻します。これは、集計ファンクションまたは分析ファンクションとして使用できます。
DISTINCTを指定する場合は、analytic_clauseのquery_partition_clauseのみ指定できます。order_by_clauseおよびwindowing_clauseは指定できません。
exprを指定すると、COUNTはexprがNULLでない行数を戻します。exprのすべての行を数えるか、または異なる値のみを数えることができます。
COUNTはNULLを戻しません。
「このファンクションは重複値およびNULL値を含むすべての行を戻します」ということから、COUNT(*)はCOUNT関数使用時の()内の式の判定をスキップするための構文のようです。
それ以上のことは書かれていません。
「SELECT * FROM [表名]」と書かれた場合の、全カラムを取得するための省略記述「*」と混同されているような気がしますが、上記を読む限り全く別の振る舞いをしているはずです。
とにかく検証してみましょう。
最初に、テーブルを作成します。
PK項目以外では、できるだけ無駄なデータアクセスが発生するようにデータ列を長めに確保します。
CREATE TABLE pt_count_test
(
pkid NUMBER(15) PRIMARY KEY
,val1 VARCHAR2(1000)
,val2 VARCHAR2(1000)
,val3 VARCHAR2(1000)
,description VARCHAR2(4000)
)
ENABLE PRIMARY KEY USING INDEX;続いて検証用のデータを作成します。
データの内容に特に意味はありません。とにかくデータで埋め尽くしています。
DECLARE
cv_dummy100 CONSTANT VARCHAR2(100) := 'ABCDEFGHIJKLMNOPQRSTUVWXYZ012345_ABCDEFGHIJKLMNOPQRSTUVWXYZ012345_ABCDEFGHIJKLMNOPQRSTUVWXYZ01234589';
cv_dummy_n CONSTANT VARCHAR2(300) := 'あいうえおかきくけこさしすせそたちつてとなにぬねのはひふへほまみむめもらりるれろ1234567890アイウエオカキクケコサシスセソタチツテトナニヌネノハヒフヘホマミムメモラリルレロ1234567890';
BEGIN
FOR i IN 1..500000 LOOP
INSERT INTO pt_count_test
(pkid, val1, val2, val3, description)
VALUES
(i,
cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || TO_CHAR(i,'FM00000000'),
cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || TO_CHAR(i,'FM99999999'),
cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || cv_dummy100 || TO_CHAR(i,'FM0,000,000'),
cv_dummy_n || cv_dummy_n || cv_dummy_n || cv_dummy_n || cv_dummy_n || cv_dummy_n || cv_dummy_n || cv_dummy_n || cv_dummy_n || cv_dummy_n
);
END LOOP;
END;
そして計測のために、下記のSQL文を実行します。
1.COUNT(*)を使用するSQL
SELECT COUNT(*) FROM pt_count_test;
2.COUNT(PK列)のSQL
SELECT COUNT(pkid) FROM pt_count_test;
3.COUNT()の中を、INDEXのない、一意となる文字列(4000byte)の列を記載します
SELECT COUNT(description) FROM pt_count_test;
4.COUNT(1)のSQL(テーブルの列を参照しない)
SELECT COUNT(1) FROM pt_count_test;
実行してみると、以下のようになりました。
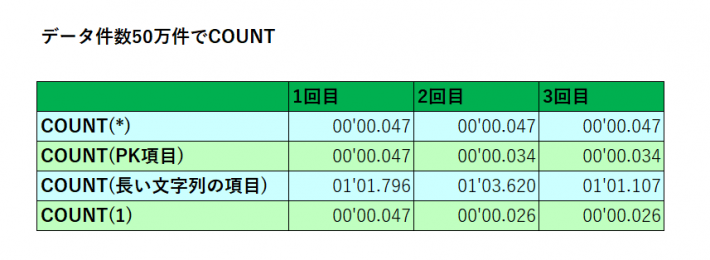
3つ目の、INDEXの無い4000byteの列を参照したパターンだけが劇的に遅く、それ以外のCOUNT(*)、COUNT(PK列)、COUNT(1)はほぼ同じという結果になりました。
COUNT(*)を使用すると遅くなるなどということはなく、全く問題ありませんでしたので、心置きなくCOUNT(*)をご使用ください。
それでもSQLが遅いようでしたら、何か他に原因があるはずです。