[番外編]機械学習プログラミング 日向坂46で顔認識してみた。@Python (2)
(番外編)日向坂46で顔認識
最近流行のAI(機械学習)でプログラムを書いてみました。
尚、この一連の記事ではOracleは全く登場しません。
この記事は、前回の続きです。
[[番外編]機械学習プログラミング 日向坂46で顔認識してみた。@Python (1)]
(https://oracle.tf17.net/plsql/?page_id=581)
2. 顔部分抽出処理
モデル作成するにあたっては、様々なサイトから収集した画像をそのまま処理するのではなく、顔の部分だけを抽出して処理する必要があります。
Pythonでは、OpenCV(CV2)というモジュールを使用して、画像から顔を検知し、その部分をだけを抽出することができます。
ここでも、処理を流して顔部分の画像を抽出して終わりではなく、画像から抽出した顔部分の画像を目視で再確認する必要があります。
元画像に複数人が同時に写っている場合は、他人の顔も検出されていますし、遠目の写真であれば顔部分を抽出すると画像サイズが著しく小さいかもしれません。
最低でも64ピクセル×64ピクセルは欲しいところです(それ以下ですと、顔の特徴が表れにくくなってしまうと思うので)。
ハードウェアのスペックに余裕があって、精度を上げたい場合はより大きなサイズで保存すべきでしょう。
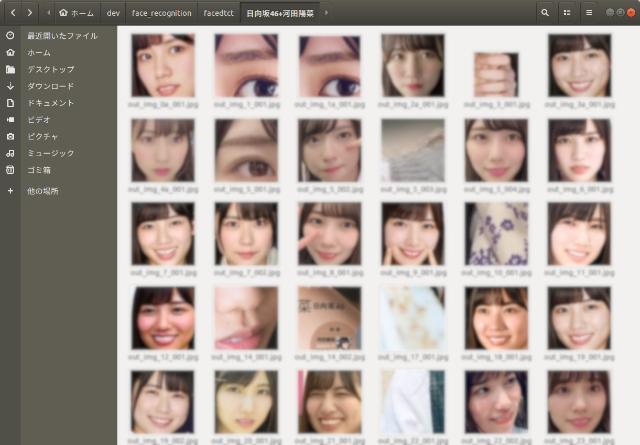
尚、画像部分はぼかしてあります。
AIというテーマでありながら、地道な人力作業が続きます。
顔認識のテーマはアイドルである必要は全く無いのですが、やはり、長時間かつ大量に見続けても苦でない人物をテーマにすることをオススメします(^^;
import os
import sys
import cv2
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
import argparse
import glob
import facerecg_image_comn as fic
# 顔画像を保存
def save_image(src_image, face_list, fn):
# 顔だけ切り出して保存
cnt = 1; # 1枚の元画像から検知した顔の数
for rect in face_list:
x = rect[0]
y = rect[1]
width = rect[2]
height = rect[3]
dst = src_image[y:y + height, x:x + width]
# 書き込み先ディレクトリの存在チェック
save_dir = os.path.join(args.outdir, os.path.basename(os.path.dirname(fn)))
if not os.path.isdir(save_dir):
print('Create save_dir:' + save_dir)
os.mkdir(save_dir)
# 顔検知結果の保存
ext_str = os.path.splitext(fn)[1]
save_path = os.path.join(save_dir, 'out_' + os.path.basename(fn).replace(ext_str, '_' + '{:0=3}'.format(cnt) + ext_str))
dummy = fic.imwrite(save_path, dst)
# plt.show(plt.imshow(np.asarray(Image.open(save_path))))
# print(cnt)
cnt += 1
# 顔検知処理メイン
def main(args):
for fn in glob.iglob(args.indir + "/**", recursive=True):
# ファイル種別チェック(拡張子jpg/pngのみ対象とする)
if ('.jpg' in fn) or ('.png' in fn):
# 画像の読み込み
print('Raeding...:' + fn)
src_image = fic.imread(os.path.join(fn))
# 顔認識用特徴量ファイルを読み込む --- (カスケードファイルのパスを指定)
cascade = cv2.CascadeClassifier("/usr/local/lib/python3.6/dist-packages/cv2/data/haarcascade_frontalface_alt2.xml")
# 顔検知の実行
face_list = cascade.detectMultiScale(src_image, minNeighbors=3, minSize=(30,30))
# 認識した顔画像の保存
save_image(src_image, face_list, fn)
def arg_parse():
parser = argparse.ArgumentParser(description='Options for scraping Google images')
parser.add_argument('-i', '--indir', default='./images',
type=str, help='input directory path')
parser.add_argument('-o', '--outdir', default='./facedtct',
type=str, help='output directory path')
return parser.parse_args()
if __name__ == '__main__':
args = arg_parse()
main(args)
このプログラムのポイントはファイルの読み書き以外は以下の2点です。
- 顔認識用特徴量ファイルの読み込み
cascade = cv2.CascadeClassifier(“/usr/local/lib/python3.6/dist-packages/cv2/data/haarcascade_frontalface_alt2.xml")
顔検知用の特徴量ファイルを読み込みます。
特徴量ファイルは、CV2のインストール時に作成されます。ディレクトリは異なるかもしれませんので、お使いの環境に合わせて変更してください。
また、顔検知用のファイルは他にも、
・ haarcascade_frontalface_alt.xml
・ haarcascade_frontalcatface.xml
というファイルもあります。他にも目だけ検知する、口だけ検知するファイルなどがあります。 - 顔検知処理
face_list = cascade.detectMultiScale(src_image, minNeighbors=3, minSize=(30,30))
以下のパラメータが指定可能です。
検知率が低い場合は、これらのパラメータを調整することで検知率を向上させられるかもしれません。- image – CV_8U型の行列.ここに格納されている画像中から物体が検出されます
- objects – 矩形を要素とするベクトル.それぞれの矩形は検出した物体を含みます
- scaleFactor – 各画像スケールにおける縮小量を表します
- minNeighbors – 物体候補となる矩形は,最低でもこの数だけの近傍矩形を含む必要があります
- minSize – 物体が取り得る最小サイズ.これよりも小さい物体は無視されます
- maxSize – 物体が取り得る最大サイズ。
また、今回の顔認識処理で多用するCV2の画像ファイル読み込み(imread)、書込(imwrite)には、Windowsで日本語ファイルパスのできないという問題があります。
そちらの対応法は下記で明らかになっており、下記、共通モジュール: facerecg_image_comn.py として組み込んでいます。
Python OpenCV の cv2.imread 及び cv2.imwrite で日本語を含むファイルパスを取り扱う際の問題への対処について
https://qiita.com/SKYS/items/cbde3775e2143cad7455
共通モジュール:facerecg_image_comn.py では、上記CV2の日本語ファイル問題の他にも、次の画像データ増幅処理、処理全般で使用する共通定数の保持に使用しています。
# ======================================
# Class:image_increase
# 画像Class
# ======================================
import os
import cv2
import numpy as np
# 定数
CATEGORIES = ["加藤史帆","金村美玖","佐々木久美","佐々木美玲","上村ひなの","丹生明里","潮紗理菜","東村芽依","齊藤京子","小坂菜緒","河田陽菜"]
NB_CLASSES = len(CATEGORIES)
IMAGE_SIZE = 128
TRAIN_DATA_PER = float(0.9)
NPY_FILENAME = './images_obj.npy'
MODEL_FILENAME = 'model_hitnatazaka.h5'
#========================================
def imread(filename, flags=cv2.IMREAD_COLOR, dtype=np.uint8):
try:
n = np.fromfile(filename, dtype)
img = cv2.imdecode(n, flags)
return img
except Exception as e:
print(e)
return None
#========================================
def imwrite(filename, img, params=None):
try:
ext = os.path.splitext(filename)[1]
result, n = cv2.imencode(ext, img, params)
if result:
with open(filename, mode='w+b') as f:
n.tofile(f)
return True
else:
return False
except Exception as e:
print(e)
return False
#========================================
#
class Image_increase:
# 画像データ保持配列定義
img = [] # 元画像データ
reimg = [] # 修正後画像データ
# 定数
BR_UP = 'up'
BR_DW = 'down'
# 画像加工モード
RESZ = 'resz'
MOZ = 'moz'
BLUR = 'blur'
MONO = 'mono'
BRUP = 'brup'
BRDN = 'brdn'
CONT = 'cont'
REMODE = [MOZ, BLUR, MONO, BRUP, BRDN, CONT] # resizeは行わない
# ======================================
# __init__
# ctmファイルの読込。DataFrameで保持する。ヘッダなし。
# ======================================
def __init__(self, infilepath, rx, ry):
self.read(infilepath)
self.resize(rx, ry)
# ======================================
# read
# ======================================
def read(self, infilepath):
self.img = imread(infilepath)
# ======================================
# out_filename
# ======================================
def out_filename(self, orgfilepath, mode):
# ファイル名部分と拡張子を取得
filename, ext = os.path.splitext(os.path.basename(orgfilepath))
# 画像加工の種類を表すmodeを挟んだ文字列を戻す
return filename + "_" + mode + ext
# ======================================
# write
# ======================================
def write(self, outfilepath, outfilename):
# 書き出し
imwrite(os.path.join(outfilepath, outfilename), self.reimg)
# ======================================
# resize
# ======================================
def resize(self, rx, ry):
copy_img = self.img.copy()
self.img = cv2.resize(copy_img, (rx, ry),
interpolation=cv2.INTER_LINEAR)
self.reimg = self.img
# ======================================
# mozaic(モザイク)
# ======================================
def mozaic(self):
mosaic_pixcel = 4
# 入力画像のサイズを取得
org_h, org_w = self.img.shape[:2]
copy_img = self.img.copy()
small_img = cv2.resize(
copy_img,
(org_h//mosaic_pixcel, org_w//mosaic_pixcel),
interpolation=cv2.INTER_NEAREST)
self.reimg = cv2.resize(small_img, (org_h, org_w),
interpolation=cv2.INTER_NEAREST)
# ======================================
# blur(ぼかし)
# ======================================
def blur(self):
copy_img = self.img.copy()
self.reimg = cv2.GaussianBlur(copy_img, (5, 5), 0, 0)
# ======================================
# monochrome(モノクロ)
# ======================================
def monochrome(self):
copy_img = self.img.copy()
# グレースケールはやり方がいくつかある。
# self.reimg = cv2.cvtColor(copy_img, cv2.COLOR_BGR2GRAY) # RGB2〜 でなく BGR2〜 を指定
self.reimg, _ = cv2.decolor(copy_img)
# ======================================
# bright(明暗)
# mode=up 明るくする
# mode=down 暗くする
# ======================================
def bright(self, mode):
copy_img = self.img.copy()
# 明るさの変化量
change_value = 64
# HSV色空間に変換(BGR→HSV)
# H:色相(Hue)、S:彩度(Saturation)、V:明度(Value/Brightness)
hsv_img = cv2.cvtColor(copy_img, cv2.COLOR_BGR2HSV)
h,s,v = cv2.split(hsv_img)
# 明るくする
if mode == self.BR_UP:
# 255以上は255に、それ以外はchange_valueを足した値に。
v[v > 255-change_value] = 255
v[v <= 255-change_value] += change_value
# 暗くする
elif mode == self.BR_DW:
# 64以下は0に、それ以外はchange_valueを引いた値に。
v[v < change_value] = 0
v[v >= change_value] -= change_value
# チャネルをマージして1つの画像にして、色変換(HSV→BGR)
self.reimg = cv2.cvtColor(cv2.merge((h, s, v)), cv2.COLOR_HSV2BGR)
# ======================================
# contrast(コントラスト)
# 画像をLAB形式へ変換してコントラストをつける
# ======================================
def contrast(self):
copy_img = self.img.copy()
# CIE1976(L*, a*, b*)色空間(CIELAB)に変換
# L=明度(0-100), a,b=補色
l,a,b = cv2.split(cv2.cvtColor(copy_img, cv2.COLOR_BGR2LAB))
# 明度の調整
clahe = cv2.createCLAHE(clipLimit=3.0, tileGridSize=(12,12))
# 新しい明度で画像を生成
self.reimg = cv2.cvtColor(cv2.merge((clahe.apply(l), a, b)), cv2.COLOR_LAB2BGR)
# ======================================
# allmodi
# 全ての種類の画像加工を連続して実施する
# ======================================
def allmodi(self, infilepath, outfilepath):
print("filepath: %s" % infilepath)
# 加工前の、サイズ変更のみ行った画像の出力
self.write(outfilepath, self.out_filename(infilepath, self.RESZ))
# 以下、画像加工処理
for moditype in self.REMODE:
print("modetype: %s" % moditype)
if moditype == self.MOZ:
self.mozaic()
elif moditype == self.BLUR:
self.blur()
elif moditype == self.MONO:
self.monochrome()
elif moditype == self.BRUP:
self.bright(self.BR_UP)
elif moditype == self.BRDN:
self.bright(self.BR_DW)
elif moditype == self.CONT:
self.contrast()
# 加工後のファイル書き出し。出力先はoutfilepath。infilepathはファイル名の取得に使用
self.write(outfilepath, self.out_filename(infilepath, moditype))
下記のようにコマンドを発行して処理を実行します。
python3 facerecg2_facextract.py -i images -o facedtct
<参考サイト>
物体検出(detectMultiScale)をパラメータを変えて試してみる(scaleFactor編)
http://workpiles.com/2015/04/opencv-detectmultiscale-scalefactor/
<参考サイト>
物体検出(detectMultiScale)をパラメータを変えて試してみる(minNeighbors編)
http://workpiles.com/2015/04/opencv-detectmultiscale-minneighbors/
3. データ増幅処理
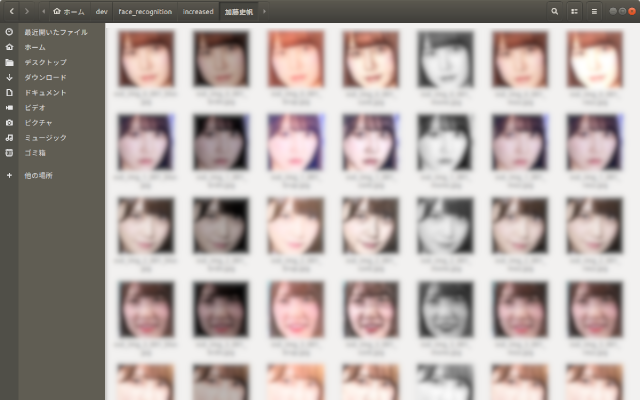
数十枚の顔画像が抽出できているかと思いますが、顔認識の精度を上げるには、できるだけ多くのサンプル画像が必要です。
顔認識では、一般的な手法として画像の増幅を行います。
今回は、以下の加工を行います。()内は使用したモジュールです。
- ガウスぼかし(cv2.GaussianBlur)
- モザイク化(cv2.resize → 一度縮小してから拡大)
- グレースケール(cv2.decolor)
- 明度変更(+)(cv2.cvtColorは色空間の変換。明度の変更は配列操作のみ)
- 明度変更(-)(同上)
- コントラスト強化(cv2.cvtColorで色空間をLabに変換後、cv2.createCLAHEで明度の変更)
これで取得できた画像を7倍に増やすことができます。
<参考サイト> console dot log カナダLOVE!なフリーランス・プログラマーのブログ!
opencv の基本的な画像変形: 全12実例!
https://blog.capilano-fw.com/?p=1990
from PIL import Image
import os, sys, glob
import argparse
import numpy as np
import cv2
import facerecg_image_comn as fic
# 画像データを読み込む
X = [] # 画像データ
Y = [] # ラベルデータ
# データをリストに追加
def data_append(data, cat):
X.append(data)
Y.append(cat)
# ファイルごとにループ、add_sampleでサンプルに登録
def make_sample(files, is_train):
global X, Y
X = []; Y = []
for cat, fname in files:
add_sample(cat, fname, is_train)
return np.array(X), np.array(Y)
def arg_parse():
parser = argparse.ArgumentParser(description='image increase.')
parser.add_argument('-i', '--indir', default='./facedtct',
type=str, help='input directory path')
parser.add_argument('-o', '--outdir', default='./increased',
type=str, help='output directory path')
return parser.parse_args()
def main(args):
allfiles = []
# メンバー名ごとに処理
for idx, cat in enumerate(fic.CATEGORIES):
# ファイル名一覧取得
print(cat)
for fn in glob.glob(os.path.join(args.indir, "*" + cat + "*", "*.jpg")):
# facerecg_image_comn クラスの呼び出しと全画像の一括加工
images = fic.Image_increase(fn, fic.IMAGE_SIZE, fic.IMAGE_SIZE)
# ディレクトリが存在しなければ作成する
if not os.path.isdir(os.path.join(args.outdir, cat)):
os.mkdir(os.path.join(args.outdir, cat))
print('outdir:' + os.path.join(args.outdir, cat))
images.allmodi(fn, os.path.join(args.outdir, cat))
if __name__ == '__main__':
args = arg_parse()
main(args)
これらの加工処理は、イメージ加工クラスとして共通モジュールにImage_increaseクラスとしてまとめています(ファイル facerecg_image_comn.py)。
このクラスは、__init__での初期化時に画像ファイルを読み込むようになっています。
また、allmodiメソッドで、読み込まれた画像ファイルに対し、上記の加工を連続して行い、ファイルに保存するようになっています。
今回は一連のイメージ加工クラスを共通モジュールとしてfacerecg_image_comn.pyにまとめしたが、クラス設計としては、定数やimread/imwriteの共通機能と、Image_increaseクラスは、ファイル毎分けた方が良いのかもしれません。