Python – 4-2. pandas(DataFrame)入出力
pandasでのデータ入出力
1. CSVファイル入出力
※ファイル名=dataframe_csv_test.csv
Data(dataframe_csv_test.csv)
key,val,col1,col2 1,TESTa,テスト1,テスト01 2,TESTb,テスト2,テスト02 3,TESTc,テスト3,テスト03
CSVファイル読込み(UTF-8(標準))
df = pd.read_csv('dataframe_csv_test.csv', encoding='utf-8')
key val col1 col2
0 1 TESTa テスト1 テスト01
1 2 TESTb テスト2 テスト02
2 3 TESTc テスト3 テスト03
文字コードがShiftJIS(CP932)の場合
df = pd.read_csv('dataframe_csv_test.csv', encoding='cp932')
==> UnicodeDecodeError: 'cp932' codec can't decode byte 0x86 in position 2: illegal multibyte sequence
※UTF-8マルチバイトを含むファイルを読込むと、上記エラーとなる。
df = pd.read_csv('dataframe_csv_test_cp932.csv', encoding='cp932')
==> key val col1 col2
==> 0 1 TESTa テスト1 テスト01
==> 1 2 TESTb テスト2 テスト02
==> 2 3 TESTc テスト3 テスト03
ヘッダ行を列名扱いしない場合
df = pd.read_csv('dataframe_csv_test.csv', header=None)
==> 0 key val col1 col2
==> 1 1 TESTa テスト1 テスト01
==> 2 2 TESTb テスト2 テスト02
==> 3 3 TESTc テスト3 テスト03
※列名もデータ扱いされる。
ヘッダを読み飛ばしたいとき
df = pd.read_csv('dataframe_csv_test.csv', header=None, skiprows=1)
==> 0 1 2 3
==> 0 1 TESTa テスト1 テスト01
==> 1 2 TESTb テスト2 テスト02
==> 2 3 TESTc テスト3 テスト03
※ 列名は連番になる。
※ データの1行目に列名が入っているので、skiprows=1を入れないと列名がデータとして読込まれる
※ pd.read_csv('dataframe_csv_test.csv', header=None, skiprows=[0]) でも同じ
skiprowsのリスト指定は、INDEX番号で任意の行をスキップできる
先頭の2行のみ読込む場合
df = pd.read_csv('dataframe_csv_test.csv', nrows=2)
==> key val col1 col2
==> 0 1 TESTa テスト1 テスト01
==> 1 2 TESTb テスト2 テスト02
CSVファイル出力
df = pd.read_csv('dataframe_csv_test.csv', encoding='utf-8')
df.to_csv('dataframe_out_test.csv')
出力結果(dataframe_out_test.csv)
,key,val,col1,col2 0,1,TESTa,テスト1,テスト01 1,2,TESTb,テスト2,テスト02 2,3,TESTc,テスト3,テスト03
2. Excelファイル読込み
read_excelで"xlsx"フォーマット読み込むためには、pandas1.1以上で、openpyxlモジュールが必要。
下記実行しておくこと。xlrdも必要(データの内容次第ではxlsxの読込に失敗する場合あり)。
明示的にopenpyxlを使用する場合は「engine=’openpyxl’」を指定
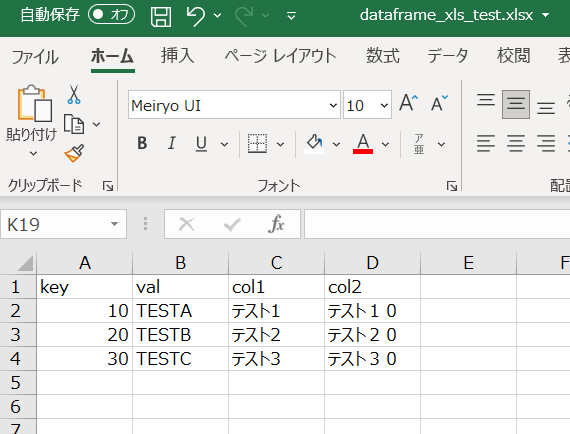
「dataframe_xls_test.xlsx」は下記内容のExcelデータ。
pip install pandas
pip install xlrd
pip install openpyxl
df = pd.read_excel('dataframe_xls_test.xlsx', sheet_name='dataframe_test', engine='openpyxl')
==> key val col1 col2
==> 0 10 TESTA テスト1 テスト10
==> 1 20 TESTB テスト2 テスト20
==> 2 30 TESTC テスト3 テスト30
df.to_excel('dataframe_xls_out_test.xlsx', sheet_name='sheetXX', engine='openpyxl')
3. HTMLファイルの読込み
基本的なデータの読込み
HTML中のTABLEタグの内容を取得する。
結果はリストとして戻される。
1つの表が、1つのリスト要素として保持される。
リスト要素はDataFrame型。
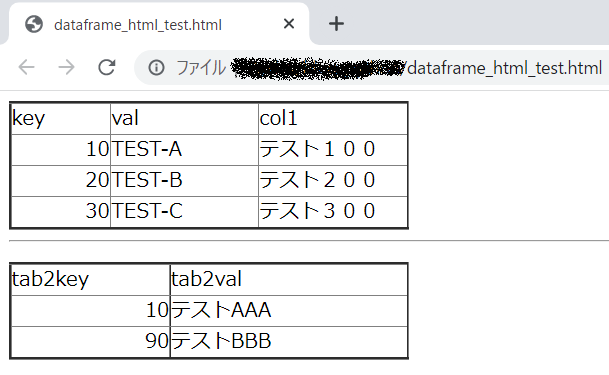
使用する「dataframe_html_test.html」は下記内容のHTMLデータ。
HTMLソースは下記の通り。
<html>
<head>
<meta http-equiv=Content-Type content="text/html; charset=utf-8">
</head>
<body>
<table border=2 cellpadding=0 cellspacing=0 width=320 style='border-collapse: collapse;table-layout:fixed;width:240pt'>
<!-- col width=75 span=4 style='width:60pt' -->
<tr>
<td style='width:40pt'>key</td>
<td style='width:60pt'>val</td>
<td style='width:60pt'>col1</td>
</tr>
<tr>
<td align=right >10</td>
<td>TEST-A</td>
<td>テスト100</td>
</tr>
<tr>
<td align=right >20</td>
<td>TEST-B</td>
<td>テスト200</td>
</tr>
<tr>
<td align=right >30</td>
<td>TEST-C</td>
<td>テスト300</td>
</table>
<hr>
<p>
<table border=2 cellpadding=0 cellspacing=0 width=320 style='border-collapse: collapse;table-layout:fixed;width:240pt'>
<!-- col width=75 span=4 style='width:60pt' -->
<thead>
<tr>
<td style='width:40pt'>tab2key</td>
<td style='width:60pt'>tab2val</td>
</tr>
</thead>
<tbody>
<tr>
<td align=right >10</td>
<td>テストAAA</td>
</tr>
<tr>
<td align=right >90</td>
<td>テストBBB</td>
</tr>
</tbody>
</table>
</body>
</html>
下記のように読み込まれる。
df = pd.read_html('dataframe_html_test.html', encoding='utf-8') # utf-8
==> >>> df
==> [ 0 1 2
==> 0 key val col1
==> 1 10 TEST-A テスト100
==> 2 20 TEST-B テスト200
==> 3 30 TEST-C テスト300, tab2key tab2val
==> 0 10 テストAAA
==> 1 90 テストBBB]
その中の一要素としてDataFrameが含まれている形となる
==> >>> print(type(df)) ==> <class 'list'> ==> >>> print(type(df[0])) ==> <class 'pandas.core.frame.DataFrame'>
表データの参照
1つの表だけを参照するには、リストの要素を指定する。
また、デフォルトではヘッダ(theadタグ)の内容が列名に設定される。
==> >>> df[1] ==> tab2key tab2val ==> 0 10 テストAAA ==> 1 90 テストBBB
ヘッダ行を指定すると、その行がヘッダ扱いされる。
df = pd.read_html('dataframe_html_test.html', header=0)
==> >>> df[0]
==> key val col1
==> 0 10 TEST-A テスト100
==> 1 20 TEST-B テスト200
==> 2 30 TEST-C テスト300
データ中の特定の列の値をindexにしたい場合は、index_colで指定する。
(tab2key列がindex列となる)
df = pd.read_html('dataframe_html_test.html', encoding='utf-8', index_col=0)
==> >>> df[1]
==> tab2val
==> tab2key
==> 10 テストAAA
==> 90 テストBBB
特定の行をスキップしたい場合は、skiprowsを使用する
(下記の例ではヘッダ行が読み飛ばされ、[10,テストAAA]列がヘッダになっている)
df = pd.read_html('dataframe_html_test.html', encoding='utf-8', skiprows=1)
==> >>> df[1]
==> 10 テストAAA
==> 0 90 テストBBB
特定の文字列を含む表のみを取得したい場合、matchが使用できる。
df = pd.read_html('dataframe_html_test.html', match='AAA')
==> >>> df
==> [ tab2key tab2val
==> 0 10 テストAAA
==> 1 90 テストBBB]
df = pd.read_html('dataframe_html_test.html', match='1')
==> >>> df
==> [ 0 1 2
==> 0 key val col1
==> 1 10 TEST-A テスト100
==> 2 20 TEST-B テスト200
==> 3 30 TEST-C テスト300]