Tips3. COUNT(*)の方がCOUNT(1)より速い?!
COUNT関数を使って件数を取得する際に、COUNT(*)と書く派、COUNT(1)と書く派に分かれます。
COUNT(1)と書く人は、恐らく若かりし頃に「COUNT(*)を使うと実行計画がFULLSCANになるので遅くなる」とか言われたのだと思います。
20年ほど前にそういうデマが流れました。
しかし、実行計画が関数の引数で変わることはまずなく、FULLSCANになるかINDEXSCANになるかは、WHERE句の抽出条件で記述内容で決まります。
このくらいのことであれば調べるまでもなく、
SELECT COUNT(*) FROM emp WHERE empno < 5000;
とでも書いて実行計画を取得すれば良いのですが。
下記のように、「SYS_C0028261601」INDEXを使用したRANGE SCANとなった実行計画が取得できます。(実行計画の取得にはhttps://apex.oracle.comのSQLワークショップを使用しました)
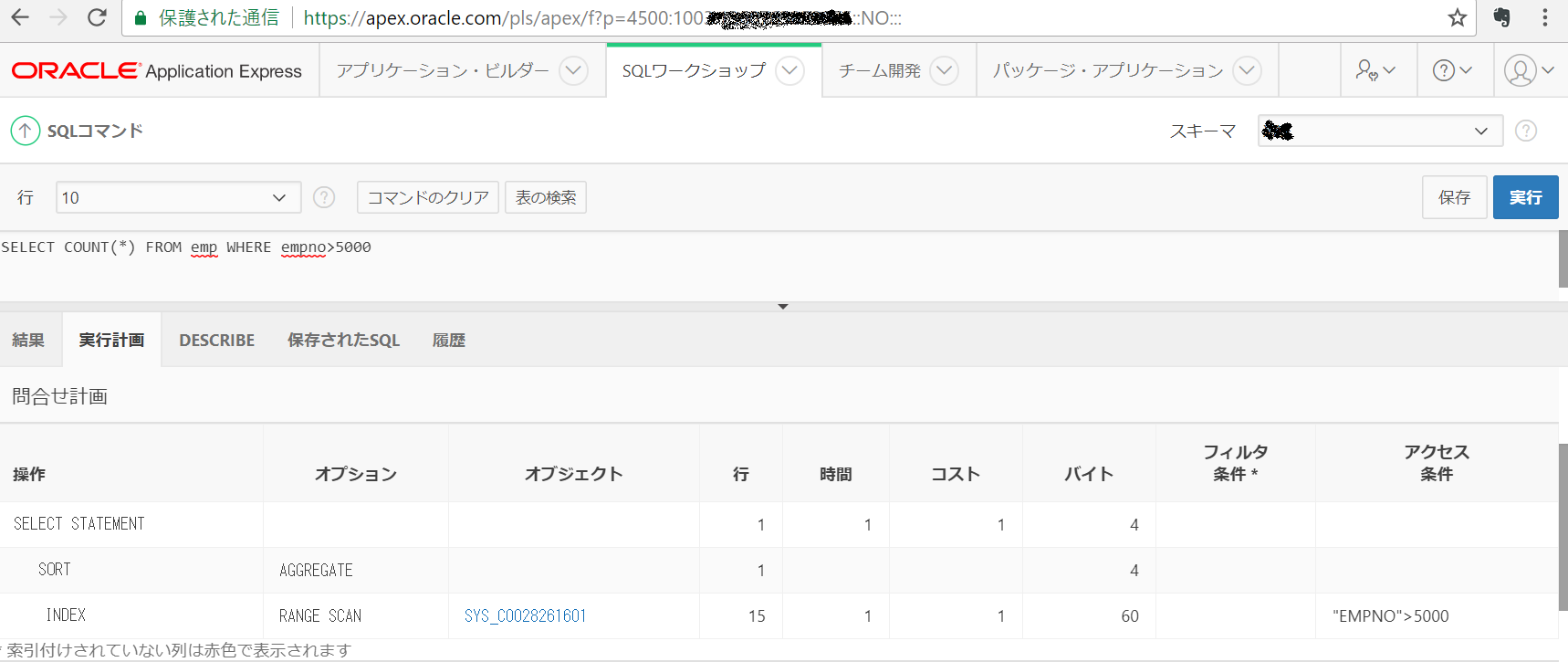
もちろん、COUNT(1)でも実行計画は変わりません。
それではCOUNT(*)とCOUNT(1)は何が違うのか。
マニュアルにはこのように記載があります。
exprを指定すると、COUNTはexprがNULLでない行数を戻します。exprのすべての行を数えるか、または異なる値のみを数えることができます。
Oracle® Database SQL言語リファレンス12cリリース1 (12.1)
https://docs.oracle.com/cd/E49329_01/server.121/b71278/functions045.htm
つまり、COUNT(1)と記載のある場合は、指定された引数がNULLかどうかの判断を行った上で、件数をカウントし、戻します。
一方のCOUNT(*)については、
アスタリスク(*)を指定すると、このファンクションは重複値およびNULL値を含むすべての行を戻します。COUNTはNULLを戻しません。
と記載されています。
つまりは何の判断も行わず、取得できた行の件数を返す、ということになります。
NULLの判断ロジックの有無がCOUNT(*)とCOUNT(1)の違いになります。
ま、昨今のハードウェア性能からすると、数千件~数万件程度のデータ量では違いは出そうにありませんが。