3-4.実装方針の検討~再処理を考慮した設計~
設計時に忘れてはいけないのが再処理を行う場合の考慮です。
バッチ処理は必ず上手くいくとは限りません。
要因は、データ、プログラム、環境、様々ですが、いずれにしても処理が正しく終了しない場合は、再処理を行うことになります。
再処理を行う場合に留意すべき点は以下の2点です。
1.連携元データの前回処理以降に発生した変動を反映できること。
2.前回処理時のデータが残り、重複してしまう状態を避ける
再処理を行うということは、初回の処理に何らかの問題があったからです。
データや関連マスタを修正した上で再処理を行う場合は、その修正が反映されなければなりません。
それと同時に、最初に誤って登録してしまったデータは削除されなければなりません。
そのための方法として、基本的な設計方針として次のように設計方式が考えられます。
キー値による再処理
よくあるのは処理対象となる年月日や年月をキー項目に含め、削除~登録を行うパターンです。
日次、月次のように定期的に行う処理の場合に適しています。
例えば、月次処理であれば、起動パラメータで処理対象となる年月を受け取り、処理の最初にその年月のデータを削除します。
こうすることでデータが重複することはなくなります。
初回実行時は1件も削除されませんが、それで問題ありません。
削除件数は0件のまま次の処理に移り、登録処理を行うことになります。
再処理の場合は、1回目の処理で登録された年月のデータを削除し、その後に同年月のデータを登録することになります。
取得元のテーブルからも最新のデータが連携されますので、データの状態を最新に保つことができます。
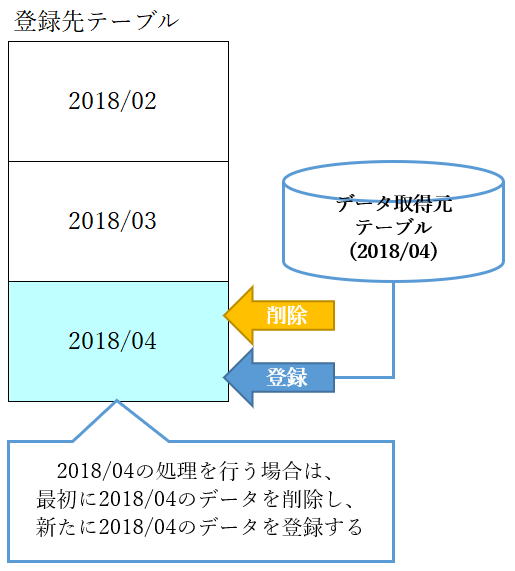
この方法は、あるキー項目で抽出可能なデータの塊に対して、削除・登録を行うため、制御がシンプルになるのがメリットです。
特に制約がなければ、この形で設計しておくのが望ましいです。
しかし、年月のようなデータのまとまりを判別するキー項目が無い、連携元のデータが(オンライン登録等)不定期に作成される、といった場合、この方法は使えませんので、別の方法を考える必要があります。
キー値による登録/更新の制御
次の方法は、連携元テーブル側にデータを一意に特定できるキー値を保持している場合に使用可能な方法です。むしろ、こちらの方式の方が一般的かもしれません。
データを一意に特定することができれば、そのキー値を保持するデータが存在していなければ新規登録、存在していれば更新を行います。

こうすることで、連携元テーブル側と登録先テーブルのデータを同一に揃えることができます。
ただし、この方法は1件ごとにデータの有無をチェックし、登録と更新を制御する必要があります。
この登録・更新の制御を自動で行ってくれるMERGE文もありますが、内部的には同じ制御をしますので、性能面では望ましくありません。
処理日時による再処理
前述のような、キー値を保持できない場合や事前の削除処理、登録・更新の制御を避けたい場合に使用します。
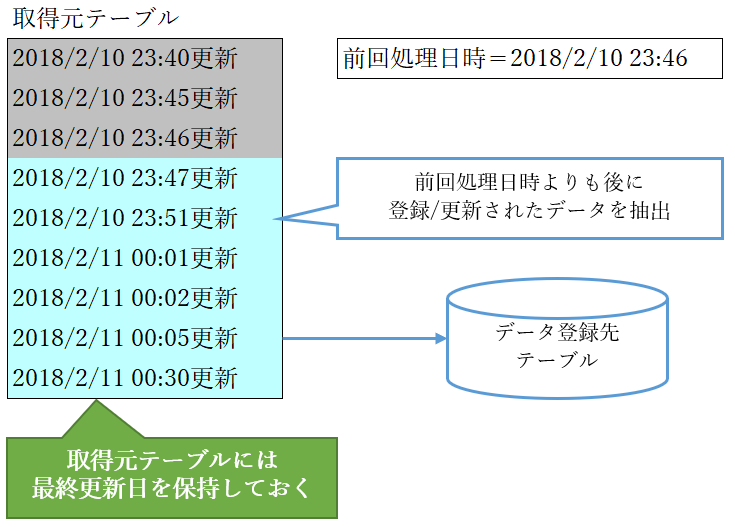
この方法では、取得元となるテーブルにはタイムスタンプ(最終更新日)を保持しておきます。
また、前回の処理日時も保持しておく必要があります。
取込処理では、前回の処理日時以降の最終更新日を保持するデータを取り込みます。
既に取込済みのデータは処理対象になりませんので、同じデータを二度取り込むことはなくなります。
また、常にデータが登録(INSERT文)になるため、制御もシンプルになります。
ただし、この方法は誤ったデータを取り込んでしまった場合のリカバリは困難です。
登録先のテーブルには、登録の度に一意となるシーケンスのIDやタイムスタンプを保持し、処理の単位を判別できるようにしておき、手動で削除するような考慮が必要になります。